Crafting a Resilient Workflow Engine with Kafka and Rollback Magic ✨
Having a workflow engine is essential when dealing with hundreds of microservices, all interconnected in various ways. When a bug arises, pinpointing it can become a nightmare.
This is where a workflow engine comes in. In this context, a workflow engine acts as a 'hub' that handles sending requests to microservices and processing their outputs. This helps mitigate issues that arise when microservices are directly connected to each other.
Creating a resilient workflow engine is challenging. There are two main approaches:
- Durable Workflows: This approach believes in infinitely retrying in case a service fails, no matter how long it takes.
- Fail-Quick workflow[1]: This approach believes that if a microservice fails, the process should fail quickly instead of retrying indefinitely.
For my purposes, I chose the 'Fail-Quick' method. Durable workflows have key setbacks that weren't suitable for my needs, particularly the lack of idempotency.
Idempotency means that a service produces the same output no matter how many times it is run, i.e. , a service
Deciding the Architecture
The basic architecture of the system was set up with rollbacks in case of failure. During my initial research, I came across the SAGA Pattern, which closely resembled the system I was planning to make. Although it is mainly used for coordinating large-scale database transactions, its core values are applicable here.
Communication
I decided to use Kafka as the message broker because it is efficient under large loads. In Kafka, I created three topics, each with its JSON format defined using Python's pydantic module:
tomanager
Messages from microservices to the manager.
class ToManager(BaseModel):
uuid: UUID
name: str
version: str # Talked about this below
service: str
function: str
status: Status
schema_version: str # Helps in future proofing
data: Any
where Status corresponds to the following enum,
class Status(Enum):
SUCCESS = "success"
IN_PROGRESS = "inprogress"
FAILURE = "failure"
The inclusion of a version field allows us to edit workflows without fear. When editing an old workflow, we can add the new one as a different version. If any process follows the old workflow, it can continue normally, while new processes use the latest version.
fromanager
Messages from the manager to the microservice.
class FromManager(BaseModel):
uuid: UUID
name: str
version: str
service: str
function: str
schema_version: str # Helps in future proofing
data: Any
tomanageredits
Messages from the workflow maker to the manager.
class ToManagerEdits(BaseModel):
name: str
version: str
schema_version: str # Helps in future proofing
workflow: Any # Talked about this in the next section
Here, the data field is flexible because the microservice output is unknown. Once received, it can be relayed to the 'next step'.
Creating the workflow
To allow users to create workflows, I built a simple graphical node editor using Flume. This lets users describe the workflow intuitively, which is easier than text-based methods.
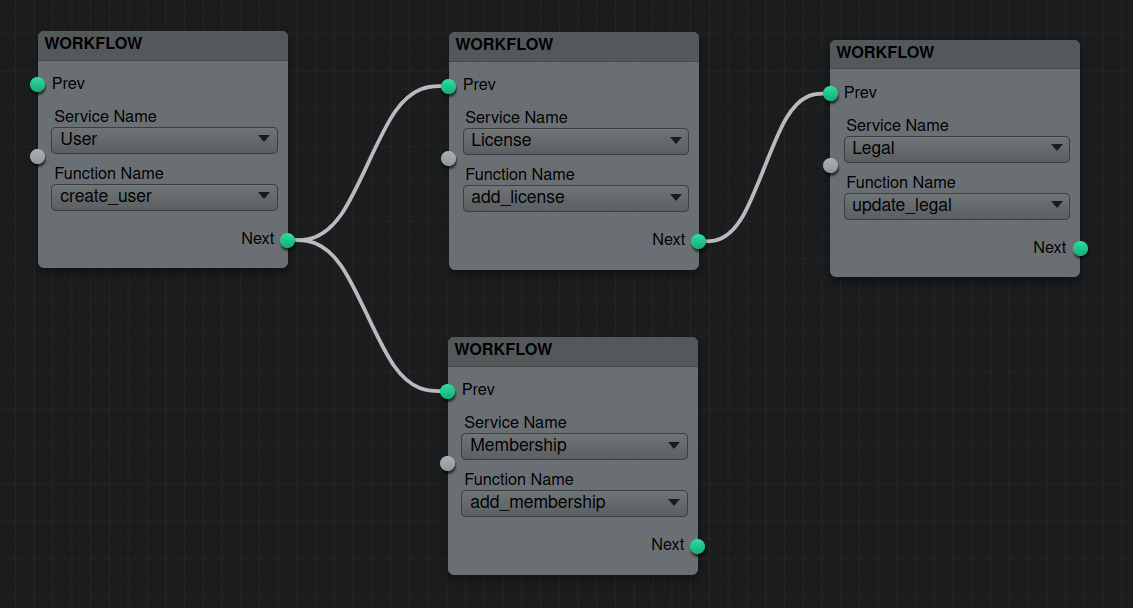
Once the workflow is drawn, it can be exported to JSON. Flume provides a JSON export that includes detailed node information. For our purposes, we focus on the inter-dependencies.
Graph Creation and Anti-Graph
Upon exporting the workflow, we create directed acyclic graphs (DAGs). We also create an 'anti-graph' by reversing all connections. This anti-graph is crucial for the rollback mechanism.
Dealing with rollbacks
Consider a scenario where our workflow includes create_user, add_license, and add_membership. If add_membership fails, we start the rollback by calling the rollback functions of add_license, followed by create_user.
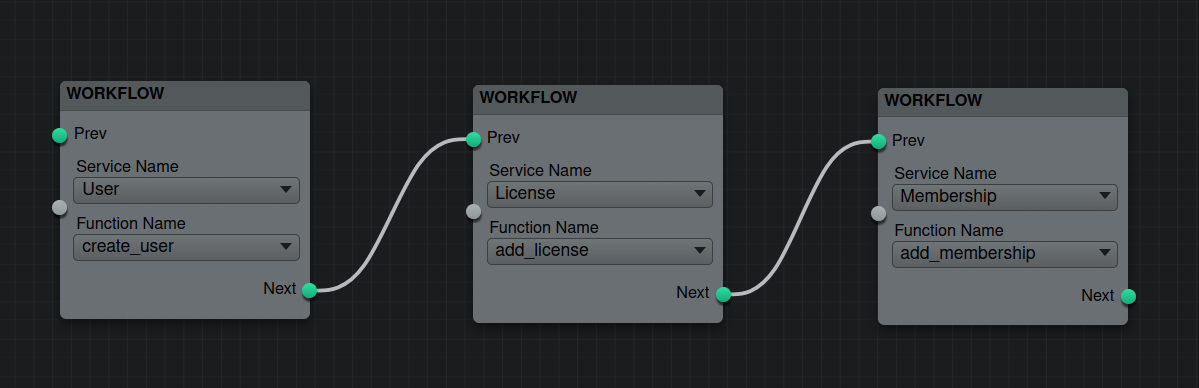
A rollback function can involve multiple steps. For example, the rollback for add_license might include remove_license and log_removal. Our system keeps track of these functions and calls them in parallel when needed:
services_function_negation_list = {
"user": {
"create_user": ["delete_user"],
},
"license" : {
"add_license": ["remove_license", "log_removal"],
},
Making the manager horizontally scalable
A single manager instance handling hundreds of requests is a recipe for disaster. To ensure scalability, the manager has two child threads:
- The first handles
ToManagerrequests, dealing with microservice responses. This thread is in amanagergroup to avoid duplicate actions. - The second handles
ToManagerEditsrequests, not in a group as edits need to propagate across all managers.
Future Improvements
Dealing with Long In-Progress Events
Handling long in-progress events is crucial to maintaining a responsive system. Here are two approaches:
- Exponential Backoff: Retry the operation with exponentially increasing delays. This helps in avoiding immediate retries and provides time for temporary issues to resolve.
- Process Termination: After a certain number of retries, terminate the process to prevent indefinite hanging. This ensures that resources are not indefinitely tied up.
Managing Branched Rollbacks
Branched rollbacks can complicate the rollback process. Here are two strategies:
- Rollback Whole Path: Rollback the entire path leading up to the failure. This ensures consistency but might be overkill if some parts of the path are unaffected.
- Partial Rollback: Rollback only the functions that have been completed. This requires keeping track of each step, making the system stateful, which can add complexity and is not ideal for a stateless system.
Handling Kafka Failures
Kafka failures can disrupt the communication flow. To handle this:
- Redundant Brokers: Set up redundant Kafka brokers to ensure message availability even if one broker fails.
- Persistent Storage: Use persistent storage to temporarily hold messages in case of Kafka outages, ensuring that no messages are lost.
Catastrophic Microservice Failures
Sometimes, a microservice might fail catastrophically and be unable to relay a 'failed' status. To address this:
- Timeout Mechanism: Implement a timeout mechanism. If a service does not respond within a certain timeframe, assume it has failed and trigger the rollback process.
- Health Checks: Regularly check the health of microservices. If a service is down, preemptively manage workflows to avoid depending on the failed service.
Implementing these improvements will enhance the reliability and efficiency of the workflow engine, making it better equipped to handle real-world challenges.
Resources
I am not sure of the actual names for these ;-;↩︎